Data Management and Data Sharing

Much of my recent work has been investigating the science of research data management, and how data management errors can affect construct validity and statistical conclusion validity.
I also give talks on the science of data management. For example, in this powerpoint, I outline some key processes and factors that you may want to consider as you develop a data management plan. If you are conducting work that involves active data collection, I provide a set of best practices that you can use.
High quality data management has a higher probability in resulting in high quality, and sharable, datasets. Data sharing is a central component of the open science landscape, and is critical to achieving transparency in research. I touch on that in this publication about Data Sharing in Education Science in AERA Open. I also talk about this connection in this invited presentation for the Society for the Scientific Study of Reading in July 2021, and this invited presentation for the Institute of Education Sciences Primary Investigator meeting in the before times (January 2020).
Interested in getting involved? I have several active projects investigating data management practices and the relations between these and open science practices. Send me an email to join us!
I also give talks on the science of data management. For example, in this powerpoint, I outline some key processes and factors that you may want to consider as you develop a data management plan. If you are conducting work that involves active data collection, I provide a set of best practices that you can use.
High quality data management has a higher probability in resulting in high quality, and sharable, datasets. Data sharing is a central component of the open science landscape, and is critical to achieving transparency in research. I touch on that in this publication about Data Sharing in Education Science in AERA Open. I also talk about this connection in this invited presentation for the Society for the Scientific Study of Reading in July 2021, and this invited presentation for the Institute of Education Sciences Primary Investigator meeting in the before times (January 2020).
Interested in getting involved? I have several active projects investigating data management practices and the relations between these and open science practices. Send me an email to join us!
Missing Data

Missing data is inevitable when we're conducting research in real-world settings. Particularly when we try to follow a sample of people longitudinally. In some recent work, I've been looking at this a few ways. First, I have a preprint up with suggestions for researchers who lost an end-of-year data collection point when schools shut down due to the pandemic. This is a special case of missing data, and I describe it HERE.
Second, along with a group, we have been developing guidelines for how to determine your missing data mechanism, and how to conduct multiple imputation. This work emerged from a 'hackathon' at the annual meeting of the Society for the Improvement of Psychological Science. The result is a user friendly document explaining the logic behind missing data decisions HERE, and a paper demonstrating multiple imputations HERE.
Planned Missingness. I've been working with current and former students to investigate one type of planned missingness design: The two-method measurement planned missingness design. In our first paper, we extended the longitudinal two-method missingness design for investigating treatment effects, and we provide both an application and a tutorial for how to fit models to your own data. That paper is now out (open access) in the Journal of Research in Educational Effectiveness. We have three more projects in the works extending this to additional models (e.g., a growth model!) and collection methods (e.g., data missing at random instead of missing completely at random).
Second, along with a group, we have been developing guidelines for how to determine your missing data mechanism, and how to conduct multiple imputation. This work emerged from a 'hackathon' at the annual meeting of the Society for the Improvement of Psychological Science. The result is a user friendly document explaining the logic behind missing data decisions HERE, and a paper demonstrating multiple imputations HERE.
Planned Missingness. I've been working with current and former students to investigate one type of planned missingness design: The two-method measurement planned missingness design. In our first paper, we extended the longitudinal two-method missingness design for investigating treatment effects, and we provide both an application and a tutorial for how to fit models to your own data. That paper is now out (open access) in the Journal of Research in Educational Effectiveness. We have three more projects in the works extending this to additional models (e.g., a growth model!) and collection methods (e.g., data missing at random instead of missing completely at random).
Within and Between Podcast

Along with my friend and co-host Dr. Sara Hart, I run a podcast about the methods and meta-science behind developmental science. The name Within and Between refers to the concepts of within-person change (individual development) and between-person change (differences between how people grow). It also is a reference to how we statistically model education data (variability within classrooms vs. variability between classrooms).
The feed of podcast episodes is available wherever you get your podcasts. You can reach the podcast on twitter at @within_between . Episodes of Within and Between is available on our website, withinandbetweenpod.com , or subscribe and listen to us just about anywhere you get your podcasts. Thank you to Nathan Archer who designed our logo!
The feed of podcast episodes is available wherever you get your podcasts. You can reach the podcast on twitter at @within_between . Episodes of Within and Between is available on our website, withinandbetweenpod.com , or subscribe and listen to us just about anywhere you get your podcasts. Thank you to Nathan Archer who designed our logo!
POWER - Providing Opportunities for Women in Education Research

I am a founding member, and current communications officer for Providing Opportunities for Women in Educational Research (POWER). The mission of POWER is to connect, support, and advocate for researchers who identify as women or non-binary in the fields of education and child development. We seek to reduce gender inequity in leadership roles, establish a professional network to maximize career advancement and retention, and enhance women’s visibility in the field. Visit POWER to learn more about what we are doing, read our resources, and consider joining us!
Mplus Helper for Latent Class Analysis (LCA)
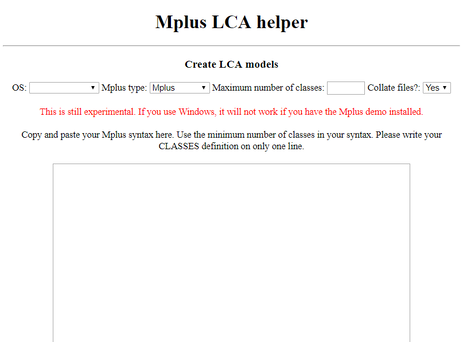
|
If you have ever run an LCA in Mplus, you know that looking through the results is cumbersome and time consuming. I worked with James Uanhoro to develop a helper tool to help you analyze the results from multiple LCA models more quickly.
Paste your syntax into this tool and it will automatically generate code to run any number of models you specify using the local Mplus software on your computer. It will also spit out a collated excel document with the model comparison statistics for you. Read more about it HERE. Cite it like this: Uanhoro, J. O. & Logan, J. A. R. (2017). Mplus LCA helper: Automating latent class analysis in Mplus. Available online at: https://mplus-output-scraper.herokuapp.com/. |
Million Word Gap
This paper was nominated as the Coolest Science Story of the year at the Ohio State University. The full paper is HERE, and the data from it is hosted HERE if you would like to play around with the data yourself.
