|
I recently received a question from a former student that is relevant to much of the way variables are created in education and developmental science, so I wanted to share it here.
Question: "In my dissertation study, participants were asked four questions (indicators) where the response options were yes = 1 and no = 0. For data analysis, I summed them together to create a measure ranging from 0 to 4. For ease, I've included the four questions here: "Was there a time in the past 3 months when you or someone in your household:
Some members of my dissertation committee are pushing back on the idea of creating a sum score. Is it OK to use this variable in a regression analysis?" Answer: There is no hard or fast rule about what you can and can’t do to variables, because data don't know where they come from. However, you do need to consider what you have done to these variables and how that distorts or represents reality. Essentially, by summing the variable you’re assuming a few interrelated things: 1) Assuming that each of these indicators has equal weight or is equally important, 2) assuming that “one more” of these indicators means the same thing regardless of which indicator it is, 3) assuming that the difference between someone having endorsed zero and 1 indicator is the same as the difference between having endorsed 2 and 3 indicators, and 4) assuming that they all qualitatively represent the same construct. There are many reasons why any of those four concepts may not be true. However, any time we take a measurement of something we simplify reality into some sort of single dimension. Your job as the expert is to figure out how that measurement translates back to reality. What I suggest here is that you write a section into your discussion about how creating the variable in this way may be different from the reality you are trying to represent. Acknowledging that this is the case, and thinking deeply about what it means for your research findings, helps to fill your responsibility as a data analyst and expert in the field.
1 Comment
In 2019, I helped to develop a series of workshops to prepare researchers to submit a development-type or efficacy-type grant. We called it "gear up for your grant proposal". One of the talks I gave as part of that workshop series was an Introduction to Power Analysis. I posted the slides to it on figshare HERE. The organizers also recorded it, and while it's not yet available, I do have hopes that the video might be one day! At the crux of my argument about power analysis is that it's not as linear as you might think. What you probably think is that you develop a research question, run a power analysis, and that power analysis tells you how many people you need to test.  In practice, power analysis is much more cyclical. It involves your budget, your research questions, analysis plan, data structure, how big of an effect you can reasonably expect to find, and the power analysis simultaneously and in combination with one another. Something more like this: 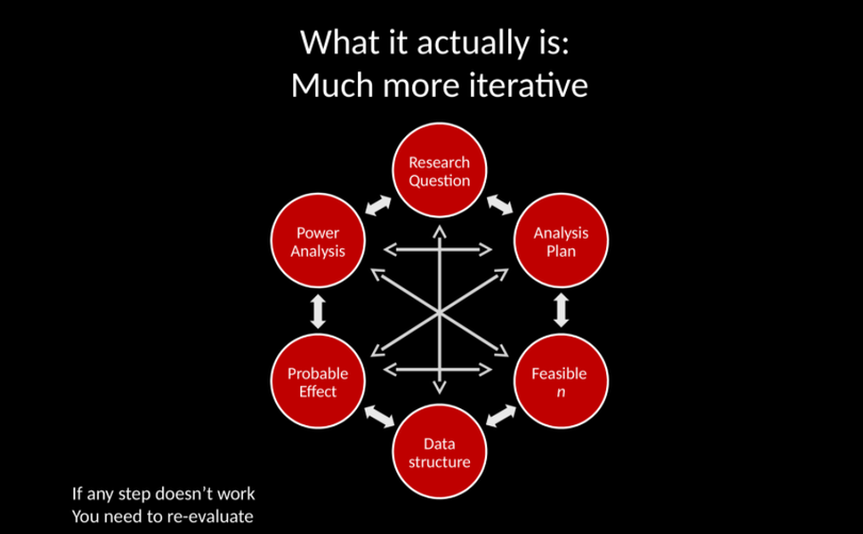 When I'm planning a study, I go around and around this interconnected web for a few days before narrowing down what we will actually do for a project. It's complex, deep thinking work. But it's also really fun. Have a read of my power-point introduction to how I approach power analysis, and consider whether using it will be useful as you are planning your own.
If you want to cite the presentation, please use the following: Logan,Jessica(2019). Introduction to Power Analysis. figshare. Presentation. https://doi.org/10.6084/m9.figshare.8236409.v1 We've been at home for four months now. Between parenting, schooling, sanitizing things and worrying that someone I love very much will get sick and die, I have been working. But the snatches of moments when I can make progress on an analysis or a paper have been few and far between. I know from conversations with my friends, colleagues, and students that I am not alone.
Do I need to keep actively parenting my children? They are relatively big as far as kids who live at home go - 12 and 8. They wouldn't burn the house down if I ignored them, and probably wouldn't do anything stupid enough to warrant a hospital visit. But I find myself _unable_ to ignore them. Desperate for a sense of normalcy and a powerful and pressing need to show them I love them...just in case. I am simultaneously in constant need of connection and space; begging them to give me time and space to work, but once I get it I am unable to do anything but miss them. This time is scary and we need each other. Under such circumstances, it is absolutely impossible to have deep thinking time. It is always interrupted by something that seems far more pressing (be it a band-aid request, a funny line in a book someone is reading, or making plans for lunch). I need to be there for them, but my patience is thinner than usual, plagued by a constant sense of guilt for not getting things accomplished. I give a hug, half listening to the story of the stubbed toe, worrying "Oh shoot, did I agree to a manuscript review? What journal was that? When is it due?". We are living, right now, under the increasingly likely possibility of someone in my house needing to teach my kids about algebra and five paragraph essays next year. Home schooling. I am such a strong advocate of the public school system, and the thought of teaching my kids at home is counter to my identity as a scholar as well as my support for equitable access to education. Even with my largely independent children, teaching them at home will take a lot of work. So much work. Even if we decide that fourth and eighth grades can just be basically skipped, and that my children can be ignored, they still need some supervision and they still need some love. I am at a complete loss as to how to continue to contribute to science, though I desperately want to do so. Under different circumnstances, I would be providing you with data. There are so many people who have this so much worse than I do as well. My BIPOC friends who are currently being asked to serve on 100 extra committees on top of their other work, life, and home demands. My friends who are parents of young children, children who would burn the house down, and who would end up with a trip to the hospital if they were ignored for a day. My friends who are supervising 45 masters students, and trying to place them as student teachers in this impossible situation. My friends who care for live-in elders, or who have children with disabilities that need doctor visits and supervision, or who are adjunct teaching and unsure if they will have a job next semester, or who have parents or a partner with the virus. Just so many "or"s. I am thinking about you all all the time. I will keep trying to convert my anxious energy into positive energy and send it out into the world. I may not write as many papers, put in as many grants, or do as many reviews in 2020/2021 as my tenure committee would like. But goodness gracious do I want to keep doing this work. I look forward to reading all of your papers, if my worry will give me more space to do it. And gosh I would love to exchange ideas with you a conference sometime. Maybe we can again someday. Please wear a mask, wash your hands, and keep staying home so we have a shot at doing things like that again. With the Institute of Education Sciences, Exploration type projects (formerly called Goal 1 projects) seek to: “identify relationships between individual-, educator-, school-, and policy-level characteristics and education outcomes, and factors outside of education settings that may influence or guide those relationships.” (IES RFP, 2020). I wanted to collect of my thoughts around what I think makes an excellent, high-quality exploration proposal. This is not a recipe blog, so without further gilding the lily, and with no more ado:
1. Clearly defined research questions that are well justified by the problem outlined in the literature review. To be fair, this one is kind of a given, and is the first thing you should do on any proposal regardless of the type or agency. I couldn’t not mention it. 2. Good proposals identify a potentially malleable factor as the outcome. The onus is on the authors to demonstrate that the factor has the potential to be malleable in the significance section. There should be at least one pilot study or other intervention study that you review that demonstrates this thing you want to study is, in fact, something that can be changed. Think about it like this: IES doesn’t want to spend their money helping to understand the potential mechanisms that are correlated with children’s height, because once kids get to school, nothing the school does will change children’s height. 3. Go back and read the second one, but this time think about your predictors. You also have to demonstrate that your predictors are potentially malleable. Some of these are easy to argue: For example, teacher qualifications are potentially malleable because the school system can change their requirements. 4. A good proposal will have sufficient variance in the predictors to actually examine what you want to examine. In short, if your key predictor is a feature of a school, then you need to make sure you have plenty of schools. If you only have three schools involved, then you can’t really run any statistical tests for your key question. For example, maybe you’re interested in principal leadership style. You need to make sure you have lots of principals; if you only have three principals, there’s a chance that all three of them will have the same leadership style and then you won’t be able to compare differences between them. There are some exceptions to this rule: Maybe you know that the three schools in question are relatively similar except for these particular (and very disparate) leadership qualities, though this research question may be better addressed with a qualitative interview. Maybe you have multiple years of data from each school both before and after they implemented a particular leadership practice (though then this is starting to sound like a quasi-experimental efficacy project). Finally, you can also potentially justify it if it’s not your primary research question. 5. You need a description of a statistical analysis for every single quantitative research question you propose to ask. That may mean you have multiple analyses described for one research question if it has multiple parts (e.g., 1a, 1b, 1c). If 1a and 1b can be answered with the same analysis, you need to say so. Don’t make the reviewer do the mental work to figure out that the two questions will probably be answered with the same analysis. Tell them. 6. Just as with the previous tip, your power analyses must be directly linked to each specific analysis. Any question you plan to answer using quantitative data should also have a power analysis. 7. You have to power your analyses for a particular effect size. It is the responsibility of the researcher to demonstrate that the effect sizes you are powered to detect are both plausible and educationally relevant. By plausible I mean that the effects you are powered to detect are in the realm of possible effects you might find. If you are powered to detect an effect of d = 1.5 (1.5 standard deviations on your outcome), you have to demonstrate using either prior literature or a pilot study of some sort that you actually have a chance to find a relation that that big. For example, if your pilot study shows a latent pathway between your key predictor and your targeted outcome of effect size d = 1.0, you either have to power for an effect of 1.0, or you need to do a lot of explaining to convince me that you could possibly find something bigger. By educationally relevant, I mean whether the effect is large enough that it means anything for the children, teachers, or schools. The effect size may be d = .50, but how big is that? For teacher or program implementation fidelity, you can translate an effect size into the number of lessons delivered. For elementary to high school children’s reading and math scores, Hill, Bloom. Black, and Lipsey (2007) provides you with benchmarks for how much children are expected to learn developmentally in any given grade. In some work with my colleagues, we replicated that work with language assessments in Schmitt et al., (2017), which provides effect size benchmarks for language development for age three to age nine. These benchmarks make demonstrating educational relevance much simpler: Powering to detect a relation that is the same size as two months of schooling is educationally relevant, where an argument of “d = .30” is not. I frequently see articles talking about the problem of the “leaky pipeline” in the STEM field (e.g., Ellis, Fosdick, & Ramussen, 2016). Women are leaving science at every stage, and there has been a big push to encouraging girls and women to stay in STEM academic fields. In THIS NSF report, we get a glimpse at the scope of the problem. We can see that women had been increasing their percentages of science and engineering doctorates up until around 2009, but hasn't moved since then: “Women’s share of S&E doctorates awarded increased from 33% in 1996 to 42% in 2009, and it has remained stable since then." Within the field of Education, the story is quite different. The percentages of women earning doctorates much higher than the rest of the sciences. Here is a figure depicting the percentages of Education Ph.D.s awarded to women from 1949 - 2012. It starts very low, around 18% in 1949, but increases fairly quickly; stabilizing at 68% around the year 2000*. 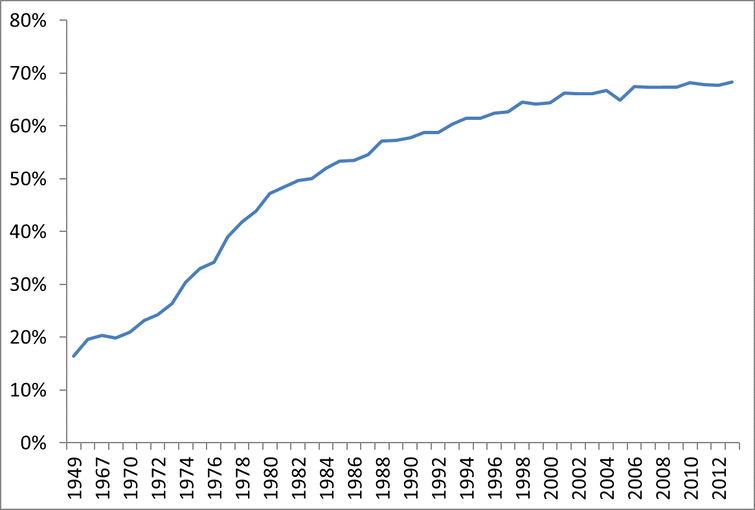 If the problem was the pipeline, then education seems to have solved it. All of these women getting Ph.D.s should translate into academic jobs. To examine that link, I looked at the NCES datalab (https://nces.ed.gov/datalab/powerstats/output.aspx). After narrowing the results to the field of Education, we can look at the percentages of professors at each rank. Here we can see two different stories. For all females in academic jobs within education, 24% of them are tenured. For all males, it was 33%. However, taking the percentages the other way, tells a seemingly more positive story. Of all academics in the field of education, 62% of them are women. But of all tenured faculty approximately half (51%) are women. 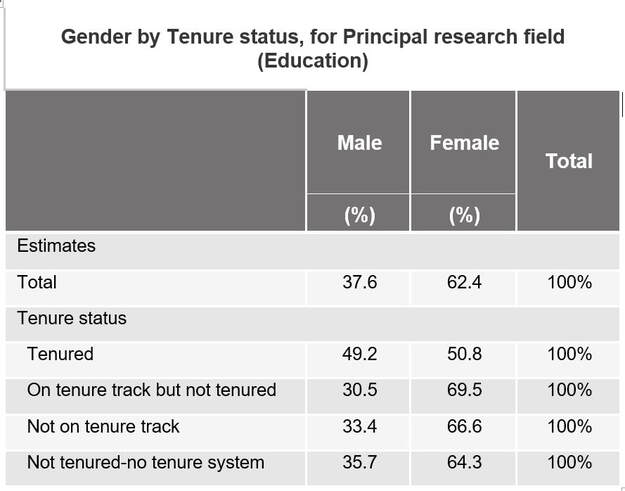 To provide some perspective, I looked up those figures for the Natural Sciences, where 25% of all faculty and 18% of tenured faculty are women. Clearly women represent more of the education sciences than they do of the natural sciences, however there is still more work to be done.
In Education, where 68% of Ph.D.s awarded to women, it is clear that the field is not disproportionally losing women at the initial job stage. Representation is approximately the same at the Ph.D. level as for faculty not on the tenure track (64% - 67%) or who are on the tenure track but not yet tenured (69%). It is somewhere during the tenure process that they leave the field. This finding is one of the reasons that I have worked with the other executive board members to found Providing Opportunities for Women in Education Research (POWER). We seek to connect, support, and advocate for women who are working in this field to help them stay in the pipeline and continue to contribute to science. Read more about POWER and our mission HERE. *Note: I pulled data from the Survey of Earned Doctorates https://www.nsf.gov/statistics/doctorates/. The datasets were called: "Doctorate recipients, by subfield of study and sex", which I pulled for each year. I harvested the number and percent of men/women for the education field from each dataset and combined them into this graph. I've been listening to the excellent podcast "quantitude" with Greg Hancock and Patrick Curran, which if you haven't done yet you should check out. In Episode 2, (Power Struggles). Patrick made the (hyperbolic) statement that all power analysis is useless. Lest you think I'm exaggerating, his exact quote is: "I think all power analysis is useless."
I was listening while washing dishes and ran across the house with wet hands to find a pen to write this quote down, because I am a power analysis believer. It's true that it can sometimes be fuzzy, and maybe more effort goes into them than is necessary, but ultimately I believe they are a good tool. I've broken down Greg and Patrick's arguments against a-priori power analysis into three basic parts: 1) Some models are so complex that there is no one pathway that represents the "effect" you need to power They argue, essentially that if you're running a complex model that Cohen's ideas about what an effect size represents doesn't even really apply. If you have a complex multi-indicator latent factor model, there are too many pathways to consider."Take a simple growth model with five indicators... what is the power of that?? Are you interested in the intercept, the slope, the correlation between the two... " When I'm running power analyses, I am often planning an analysis with complex, multi-indicator latent factor models, with students nested in classrooms. Sometimes there is a planned missing data design also housed within that latent model. These are extremely complicated. But in the end, my research questions, my hypotheses, can almost all be confirmed or refuted based on the statistical significance of a particular pathway (or pathways). If I can't, then I need to go back and re-state and re-think my question. 2) Power is specific to the analysis you want to run Yes. This is why the specificity is even more important. Do you want to know if third graders grow in their language skills less than second graders do? Then you need to fit a growth model, and you need to estimate the power you have to detect the pathway that represents that difference. Maybe that's a predictor of the latent slope. You can power for that. Maybe it's a multiple group model, and you'll constrain to see if the slope factor should be forced to be equal across your groups or allowed to vary. You can power for that too. I do this with simulations. Where the values of those simulations are seeded by pilot work or other large scale studies that have used the same or similar measures. I use the variance almanac to determine the intra-class correlation due to schools (when that is relevant). I use this delightful article to determine whether my effect sizes are meaningful or important or at all interesting. 3) Power is specific to features of the data: "Power depends on the communality estimates; the multiple R-squared. It increases the higher your R-squared is for your indicator" Agreed, and this is why I always present a power analysis under multiple scenarios. I will always estimate my power to detect the critical pathway for a given hypothesis both with and without covariates included, for different levels of attrition, for different key variables of that particular construct. And so... To sum up, I do agree that running a power analysis for an entire model is useless. But it is useless because if the only power analysis you can think to run is one for the model itself, then you probably don't have a very well defined question. For any one study, I will report two to three power analyses for each and every hypothesis. I think our differences in opinion can be boiled down to differences in funding mechanisms. The NIH gives you one paragraph, while IES, who I write most of my grants for, expects something closer to a page with a table dedicated to the power analysis. It's also different because I have the luxury of frequently working with randomized control trials. Usually a primary aim of the study is to determine whether a treatment group is different from a control group. Don't get me wrong. A lot of my time is spent on power analysis. If Patrick and Greg can convince the federal funders to drop power, or to switch to an emoji-based system, I could learn to knit or something with all of the extra time I would have on my hands. But for now, if you're in need of a power analysis, try mapping your research question on to the actual equation or latent path model you intend to run. Where in that equation or on that diagram could your hypothesis be disproven? If you don't know, try writing a better, more specific question. I've finally joining the preregistration party (here and here), I wanted to take a few minutes to write about my experience. I chose to use the Open Science Framework (OSF) to file my pre-registrations. Most of the various preregistration forms on the OSF are set up to intake information and plans for a project before it is executed, as if you are conducting a registered report. However, I immediately put myself at a disadvantage for the preregistration experience for two reasons: First, both of my projects relied on a new analysis of already collected or existing data. Second, my goal with both of these projects was to preregister the plan for the analysis of data for a particular paper, and not for an entire study.
The (Brightstart Impact Paper) is the culmination of a five-year randomized control trial funded by the Institution of Education Sciences (IES). Yes I said culmination and I said five-year, so the plans for how to collect this data had long been settled by the time I wanted to preregister the analysis plan. However, with IES grants, we are required to include extensive and detailed documentation of the plans not only for the data collection, but also for the sample size, and analysis plans. So we did have a detailed record of the study design and analysis plan, it had just never been published. In that way, completing some of the preregistration paperwork was relatively straightforward. After reaching out to twitter for suggestions, I landed on the "AsPredicted" version of the preregistration form. The "nine questions" on this form are, to me, rather bizarrely ordered on the OSF and omit some key information. I can see how if I was planning an "in-lab" experiment with undergraduates that this might be a good option, however for trying to complete this about a complex study for which the data had already been collected I ran into several road blocks. I recently published my second registration (Unique contribution of language gains to children’s kindergarten and grade 3 reading skills), and ran into the same issues again so I wanted to document them here. First, is a very small problem, but there was no place to include authors!?! I had to include our authors in the "other information" section. That seems completely bizarre and fixable. Second, I was surprised that this form asks for no background or motivating information. The methods and analysis plan should be completely dependent on that background, and without it I find it difficult to determine whether the study design or analysis plan is appropriate. Third, there was no dedicated space to list information about predictors and covariates in the model, so I tucked them away in the analysis section. Third, some of the sample ascertainment questions are tough with secondary data - the plan is to use every single data point I can get my hands on, and I have no idea if that will be 800 or 8,000 data points, and I won't know until I get into the data. For those sections, I settled on reporting a power analysis for a minimally meaningful effect size. In all, I plan to continue pre-registering my planned papers, even with these road blocks. I think a dedicated form for secondary analysis would be very beneficial for the field of education as a whole. A group of researchers at the Center for Open Science has already developed a template, available HERE, and I look forward to using it once it is functional. A disclaimer to the negative tone of this... review?... I really don't like fitting my ideas into superseding categories, and generally I find filling out forms to be anxiety provoking at best. Manuscript submission portals make me want to crawl under my desk and hide. I'm hoping that with continued practice I will get over that fear for this process. Time will tell. 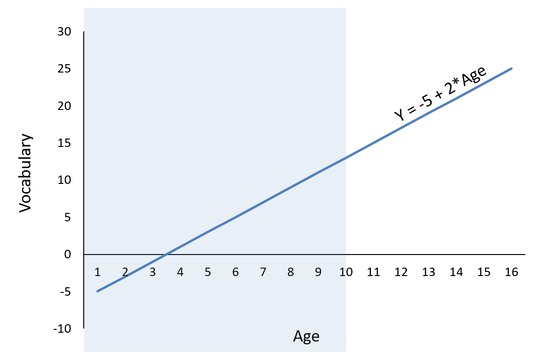 I'm teaching regression right now and a question that comes up a lot is how an intercept can be negative when the outcome has a range of scores of something like a grade on a vocabulary test in percent correct (0-100%). Worse, sometimes the regression suggests that the negative intercept is significantly different from zero! Can we really conclude that there are people who got a negative score on a vocabulary test?
Regression is based around the idea of model comparisons; where models with added predictors are compared to an unconditional model (a model with no predictors) to determine if better fit has been achieved. In the unconditional model, each person’s observed score on the Y (the outcome) is always equal to the mean of Y (represented as B0) plus error: Y = B0 + e Because B0 is equal to the mean of Y, in our hypothetical example of percentage correct on a final test, the intercept will never be negative. It could be really small if your class of students absolutely bombed their test, but it won't ever be negative. But we don't really ever interpret unconditional models. In a regression, you will always have at least one predictor. We add a predictor in an attempt to make the error smaller. In other words, we attempt to explain more of the error, and better fit the observed data points. So let's suppose that my vocabulary test is completed by 200 students, aged 10-15. I generally expect that older children will have larger vocabularies (and thus, higher scores on this vocabulary test). When we add a predictor to this equation, it is now a conditional model. In regression, the conditional model predicting vocabulary from age will look like this: Y = B0 + B1*age + e Where Y = the expected vocabulary score for someone who is zero years old. Why for someone who is zero? Because if the x-value plugged in for age is zero, then the weight (B1) is reduced to zero, and so Y = B0. The key phrase here is “someone who is zero years old” because it is what makes the expected score of Y conditional. The expected value of Y (and so the estimate of B0, which is also called the Y-intercept or often just “intercept”) is always equal to the mean of Y when all predictors are zero. So in our hypothetical example, our age variable ranges from 10-16, and so does not include zero. If the age coefficient is significantly positive, there's a strong possibility that the intercept may be negative. Inventing some results, I graphed them at the right: With the equation Y = -5 + 2* Age. Here I've estimated that a 10 year old has an expected vocabulary score of 15, and that every year age increase corresponds to an expected 2 point increase in vocabulary score. That means we have a negative intercept (B0 = -5). The negative intercept is completely possible, because we are trying to estimate the vocabulary score of... a newborn baby. The whole shaded part of that figure represents a place on the distribution where we don't have any data. So. Only interpret your intercept, negative or not, when the zero point lies within the observed range of your data. If it doesn't, you have two choices. 1) Don't interpret it, just ignore it. or 2) re-center your predictors so that they all do contain your zero point, and now you can interpret the intercept. What's centering? We'll do that another day. In his post “data analysis is thinking, data analysis is theorizing” Sanjay Srivastava touches on several topics that resonated with my sense of the importance of the work that my colleagues and I do in the field of methodology. Sanjay discusses the Many Analysts, One Dataset study, which found that even with the same dataset and same hypotheses, different analysts came to different statistical conclusions. Sanjay states: “the variability was neither statistical noise nor human error. Rather the differences in results were because of different reasoned decisions by experienced data analysts” This well-articulated point highlights some of the important theoretical work that is done by statisticians and methodologists. It also highlights what I believe is so wrong and broken in the relationship between content researchers (what I am using to refer to those researchers who primarily study an academic area such as personality, family relationships, or poverty) and statisticians or data analysts.
An applied statistician is essentially always working outside of their area of expertise. Working outside of your area of expertise is not fun and is not easy. Imagine if to get your summer salary covered you were asked to write two papers in a completely new field. Do you study social psychology? Congratulations, this summer you’ve been assigned to collect data and write two papers about the diversity of insect species in the wetlands of Florida. It’s ludicrous. You wouldn’t even know where to start. This is similar to what you ask statisticians to do when they are involved in a project at the last minute. You essentially say: “Here’s an area of work I’ve spent the last 10 years of my life thinking about, can you tell me if my intervention works by the end of the month?”. Yes, I absolutely can, but if this is the first time you’ve talked to me, I can pretty much guarantee you’re not going to like my answer. All of the underlying groundwork; hundreds of methodological choices have been made without my input. Making decisions at this point is the equivalent of dropping me in a Florida wetland to count bugs. I am going to do it wrong; make the wrong choices, otherwise invalidate your best intentions. My goal here is not to scare you. Rather my goal is to encourage you. To tell you that science can be better. That you can get closer to answering the questions you really want to answer with a little more forethought. When you want to design a study, you should reach out to someone with expertise in how to design a study. My call to content researchers is to consider the methodologist as a research partner with an area of expertise, and not as someone who can provide some last minute help to run a model. Statisticians will make the wrong choices, and will analyze your data wrong if they don’t understand the underlying theories behind what you’re trying to do, and what new knowledge you’re trying to bring into the world. When you are designing a quantitative study, you need to consider the potential power you have to detect effects. Any power analysis you run will have four components:
In education,we also often need to consider multiple factors like how the data are structured, like how random assignment occurred (if it's happening at all), or whether kids are nested in classrooms. These factors add additional elements to these equations. In this powerpoint presentation, I go over some of the features of how to calculate a power analysis when you're planning education research. |
Archives
June 2022
Categories |
 RSS Feed
RSS Feed
